
In our last post, we went over a range of options to perform approximate sentence matching in Python, an important task for many natural language processing and machine learning tasks. To begin, we defined terms like tokens (a word, number, or other discrete unit of text), stems (words that have had their inflected pieces removed based on simple rules), lemmas (words that have had their inflected pieces removed based on complex databases), and stopwords (low-information, repetitive, grammatical, or auxiliary words that are removed from a corpus before performing approximate matching).
We used these concepts to match sentences via exact case-insensitive token matching after stopword removal, exact case-insensitive stem matching after stopword removal, and exact case-insensitive lemma matching after stopword removal. These methods all work by transforming or removing elements from input sequences, then comparing the output sequences for exact matches. If any element of the sequence differs or their orders change, the match fails.
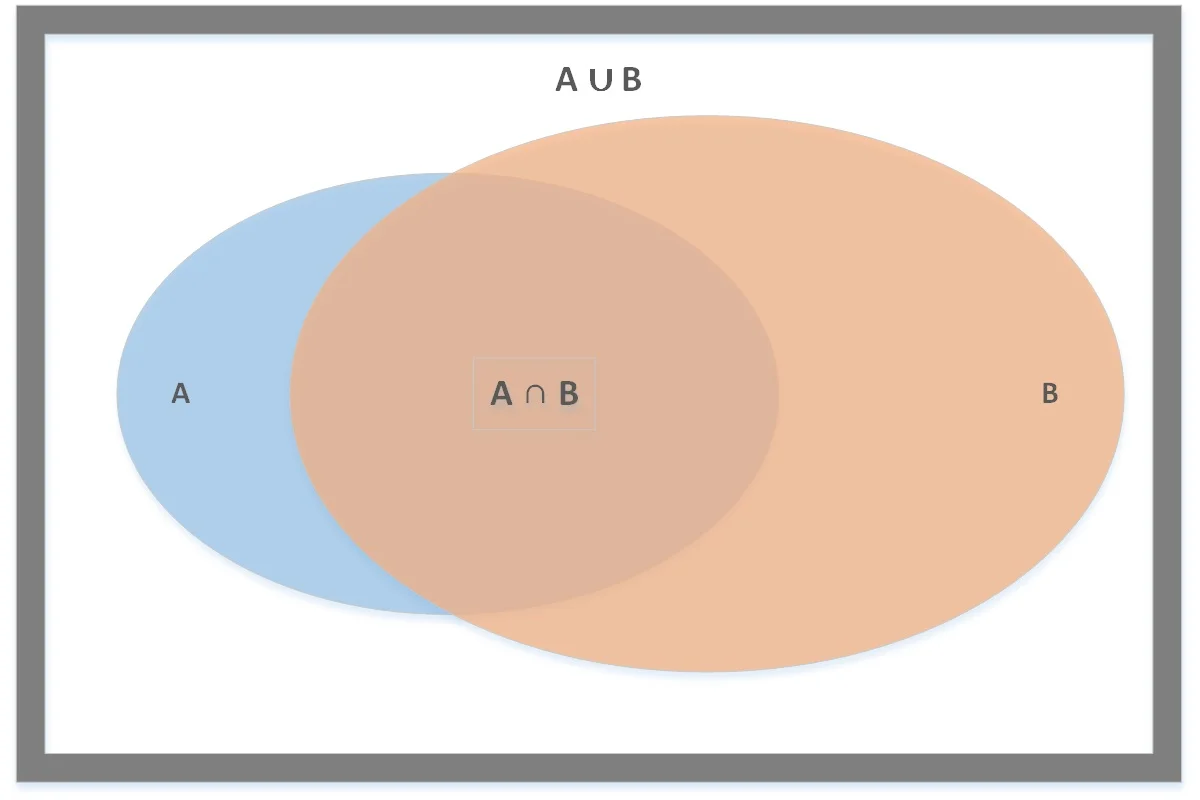
In order to locate more true positives, we need to relax our definition of equivalence. The next most logical way to do this is to swap our exact sequence matching with a set similarity measure. One of the most common set similarity measures is the Jaccard similarity index, which is based on the simple set operations union and intersection.
We are comparing two sentences: A and B. We represent each sentence as a set of tokens, stems, or lemmas, and then we compare the two sets. The larger their overlap, the higher the degree of similarity, ranging from 0% to 100%. If we set a threshold percentage or ratio, then we have a matching criterion to use.
Let's say we define sentences to be equivalent if 50% or more of their tokens are equivalent. When we parse sentences to remove stopwords, we end up with sets like {young, cat, hungry} and {cat, very, hungry}. The Jaccard index numerator counts shared items (2: cat, hungry) and the denominator counts total unique items (4: young, cat, very, hungry). Therefore, our Jaccard similarity index is 2/4 = 50%.
In Approach #4, we apply case-insensitive token set similarity after stopword removal. Instead of looking for an exact match between the sequence of tokens, we calculate the Jaccard similarity of the token sets. This allows us to survive small insertions or order changes in the sequence.
# Imports
import nltk.corpus
import nltk.tokenize.punkt
import nltk.stem.snowball
import string
# Get default English stopwords and extend with punctuation
stopwords = nltk.corpus.stopwords.words('english')
stopwords.extend(string.punctuation)
stopwords.append('')
# Create tokenizer and stemmer
tokenizer = nltk.tokenize.punkt.PunktWordTokenizer()
def is_ci_token_stopword_set_match(a, b, threshold=0.5):
"""Check if a and b are matches."""
tokens_a = [token.lower().strip(string.punctuation) for token in tokenizer.tokenize(a) \
if token.lower().strip(string.punctuation) not in stopwords]
tokens_b = [token.lower().strip(string.punctuation) for token in tokenizer.tokenize(b) \
if token.lower().strip(string.punctuation) not in stopwords]
# Calculate Jaccard similarity
ratio = len(set(tokens_a).intersection(tokens_b)) / float(len(set(tokens_a).union(tokens_b)))
return (ratio >= threshold)In Approach #5, we replace tokens with stems, which allows us to equate words with a common meaning. By switching from tokens to stems, we match additional sentences that differ only in word inflection.
# Imports
import nltk.corpus
import nltk.tokenize.punkt
import nltk.stem.snowball
import string
# Get default English stopwords and extend with punctuation
stopwords = nltk.corpus.stopwords.words('english')
stopwords.extend(string.punctuation)
stopwords.append('')
# Create tokenizer and stemmer
tokenizer = nltk.tokenize.punkt.PunktWordTokenizer()
stemmer = nltk.stem.snowball.SnowballStemmer('english')
def is_ci_stem_stopword_set_match(a, b, threshold=0.5):
"""Check if a and b are matches."""
tokens_a = [token.lower().strip(string.punctuation) for token in tokenizer.tokenize(a) \
if token.lower().strip(string.punctuation) not in stopwords]
tokens_b = [token.lower().strip(string.punctuation) for token in tokenizer.tokenize(b) \
if token.lower().strip(string.punctuation) not in stopwords]
stems_a = [stemmer.stem(token) for token in tokens_a]
stems_b = [stemmer.stem(token) for token in tokens_b]
# Calculate Jaccard similarity
ratio = len(set(stems_a).intersection(stems_b)) / float(len(set(stems_a).union(stems_b)))
return (ratio >= threshold)In Approach #6, we replace stems with lemmas and also ignore all lemmas that do not correspond to nouns. The motivation is that we care about the "things" in the sentence, not the "actions" — using only noun lemma sets allows us to achieve more positive matches while controlling false positives.